


Does your digitization partner know your collection?
Search results, whether too broad or broken, often reveal how well archivists know your material. Proper use of metadata and tagging, from general information to specific facets only relevant to your collection, make all the difference.
For a company like Anderson Archival, the digitization process is only the first part of your digital collection’s story. Before beginning each project, we sit down with the owners and have a series of discussions to determine why this collection needs to be preserved digitally and how researchers, readers, teachers, learners, and the casually curious will interact with the digital library.
What is a digital library?
We dig deep into use cases. Who wants to access this collection and who do you want to provide access to? How and when will the collection be accessed? Do the majority of potential users use browsers, or are they on the cutting edge of technology, wanting something to work seamlessly on desktop, tablet, and phone? Will you require a subscription for access, keeping some of the collection behind a paywall? And, most important to this step, what information should be included in metadata and tagging?
What is Metadata Tagging?
Metadata is data about the collection, such as author, date, title, section, topic, era, etc. Tagging is a technical means to mark up the collection with this metadata.
Advanced or faceted search is built upon tagging. Metadata tagging breaks documents into pieces of information that the search engine utilizes to allow the user to refine their results. For example, in a collection of periodicals, most of the metadata is already present in the text of the first pages.

If this New York Times page was part of a digital library, it would include at least three data layers:
- The visible image.
- Searchable text.
- Helpful metadata tags.
Where HTML tags instruct a system how to display a certain document, XML metadata tagging tells a search engine what it is looking at, and where on the page search terms, topics, authors, and any other information can be found.
What is Faceted Search?
Generic, bulk search does a decent job finding exact text matches within documents and providing those documents as results. Advanced faceted search takes these results to another level.
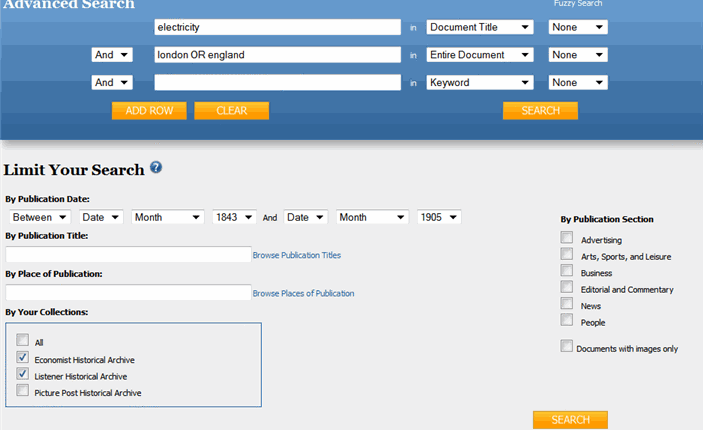
If you’ve ever worked with a search page that looks something like the example above, you know the power of faceted search! Building the information and commands into the documents makes a search like this function.
Take the New York Times example above. This page, along with every article on it, would be tagged with the date, volume, and number of the particular issue. That way, if a user were to search for the word “armistice,” but limited the results to 1918, the main story on this page would appear in the results. If use cases indicated that users would benefit from being able to search by subject (WWI, Kaiser Wilhelm, etc.) even if the referenced term did not appear in the original text, tagging that information in the metadata would make sure that it appeared as a result of those searches.
The author is important to many collections. But what happens when that author is published under a married name, or a pseudonym? Most users would want complete results, regardless of how a name is printed on a page. This takes research, time, and care.
Read more about Anderson Archival’s approach to search!
The terms and searches themselves vary depending on the collection and the users accessing it. Identifying these categories takes ongoing discussion and collaboration between the collection owners and digitization team. Because of the flexibility of tagging, almost any value can be marked. For example, a collection of Shakespeare’s plays may benefit from tagging each line, and encoding it with the line number. A user could search Act 3, Scene 1, line 61 in Romeo and Juliet and get the same result, “Ay, ay, a scratch, a scratch,” regardless of printed version referenced. Tags can identify where a sentence starts and stops, or, for something like Romeo and Juliet, the start and stop of lines of text, or when characters start and stop speech.
Your digitization company needs to know your collection inside and out in order to create metadata that powers an effective and comprehensive search.
What Does The Metadata Process Look Like?
When working with a digitization company, the process of building metadata and tagging the collection is ongoing. Once the process has started, you and your archival team may need to go back to the beginning to review your goals and refocus based on new findings.
Common steps in the process are:
- Define Use Cases. How is the digital collection going to be used, and by whom? Who is going to use the digital collection? How can search cater to the broadest number of potential users? What tags and information would benefit searchers and users?
- Build Data Dictionary. Also known as a metadata repository, this living document will hold all of the potential tags that will be employed in the collection.
- Accurate and Comprehensive Tagging. With the full knowledge of your collection, archivists spend time tagging and checking one another’s work for quality assurance.
- Implementation of Search. Once tagging is complete, archivists conduct thorough testing on whatever platform you choose to house your collection, confirming the quality of the user experience.
At each stage, your digitization company should grow to know your collection better. In the end, the accurate search and clear display of your collection will be a testament to how dedicated your team has been, providing an incredible return on your investment in digitization.
Are you looking for an innovative search solution for your collection? Contact Anderson Archival by phone at 314.259.1900 or email (info@andersonarchival.com) today.